To any afflicted CEO in my readership: I want to cure your AI psychosis.
⚠️ First, a disclaimer ⚠️ This post does not discuss legitimate medical issues; I'm not a doctor and none of this is medical advice. Talk to a real medical doctor if your mental health is in question.
As a quick aside, I'm experimenting with recording my blog posts for YouTube. So if you'd rather see that, here it is:

Instead, let's talk about the fun kind of AI psychosis. The kind where people see LLMs as a genie-in-the-bottle, able to grant any wish.
Aaron Levie, the CEO of Box, recently tweeted that CEOs are uniquely prone to this kind of AI psychosis. He says that CEOs do not perform the "last mile" of work. They never see the effort required to coax LLMs to perform useful work. They just see the happy path. "Here ya go boss! I made this prototype with an LLM prompt, just like you asked."
If you're a CEO and you're working daily with LLMs and you have a good sense of their limitations: I hope you're having a good day! You can close the tab. But for the rest of you, buckle up, because we need to talk.
Anyone riding the NYC subway these days can observe this themselves. The ads plastering the trains are preposterous. They make promises like, "make an entire presentation with a single prompt." Obviously this is disingenuous. But there must be some subway riders influenced by this, at least enough to visit the website. And those people must somehow be responsible for inking SaaS contracts. And you might wonder, "Why can't it? Why can't it make a whole presentation with a single prompt?" Let's save that question for the end of this post. We can decide together whether it's just "a single prompt" or there is an incredible amount of hidden work.
The answer has to do with two questions.
- How easily can the LLM supplement its context?
- How quickly can the LLM verify its output?
But we'll talk about that later.
Let's go back to the beginning.
At release, ChatGPT could do things that no computer had ever done before. You could type any request you wanted, and it could do it. Need to write an email to a business? ChatGPT can do it. A poem about your friend in the style of Walker, Texas Ranger? Giddyup partner.
So why didn't the entire world lose their jobs at this point? Because LLMs were absolutely useless for real work. They confidently lied, over and over. They fabricated citations. They became legitimately unhinged if a conversation extended more than a few rounds of back-and-forth. They couldn't follow simple step-by-step instructions without getting lost. It generated code that wouldn't even compile, or used imaginary APIs on imaginary libraries. They couldn't count the letters in a word. They failed at trivial reasoning exercises. Sometimes their rudimentary safety checks prevented you from doing mundane tasks, but other times the LLM urged people to kill themselves. And that's an incomplete list of their shortcomings. They had some utility, but the outputs were largely a novelty.
But LLMs have improved so quickly over the past few years. Each of the above problems have better mitigations, and LLMs have gained new capabilities. They got chain-of-thought reasoning strengthened with reinforcement learning. They can call tools. There are now protocols that allow LLMs to interact with your data in any application. Every few months they get model upgrades that supercharge its abilities.
And they are world beaters. They are solving novel math problems that humans have been trying to solve for decades. They can perform complicated research tasks and produce convincing summaries of the results. They beat software engineers in coding competitions. And by all accounts, they can write college-level essays.
So I don't blame anyone for drawing the trend line from these capabilities and saying, "if an LLM can perform high-level mathematics, or implement a complicated step-by-step pull request, then surely it can do any job."
But, I have to level with you: in all that time, with all of those improvements, they have gone from "useless for real work" to "somewhat useful for real work. They cannot produce a final product unsupervised if the quality matters at all.
They will save some time if you are skilled at using LLMs. But LLM use is a skill, and it's a skill with a low skill floor and a high skill ceiling. An unskilled person will take longer to produce a professional-level output than if they had done it themselves. You can also be a LLM veteran and do something that worked before, and it just produces a worse result this time. Unlucky.
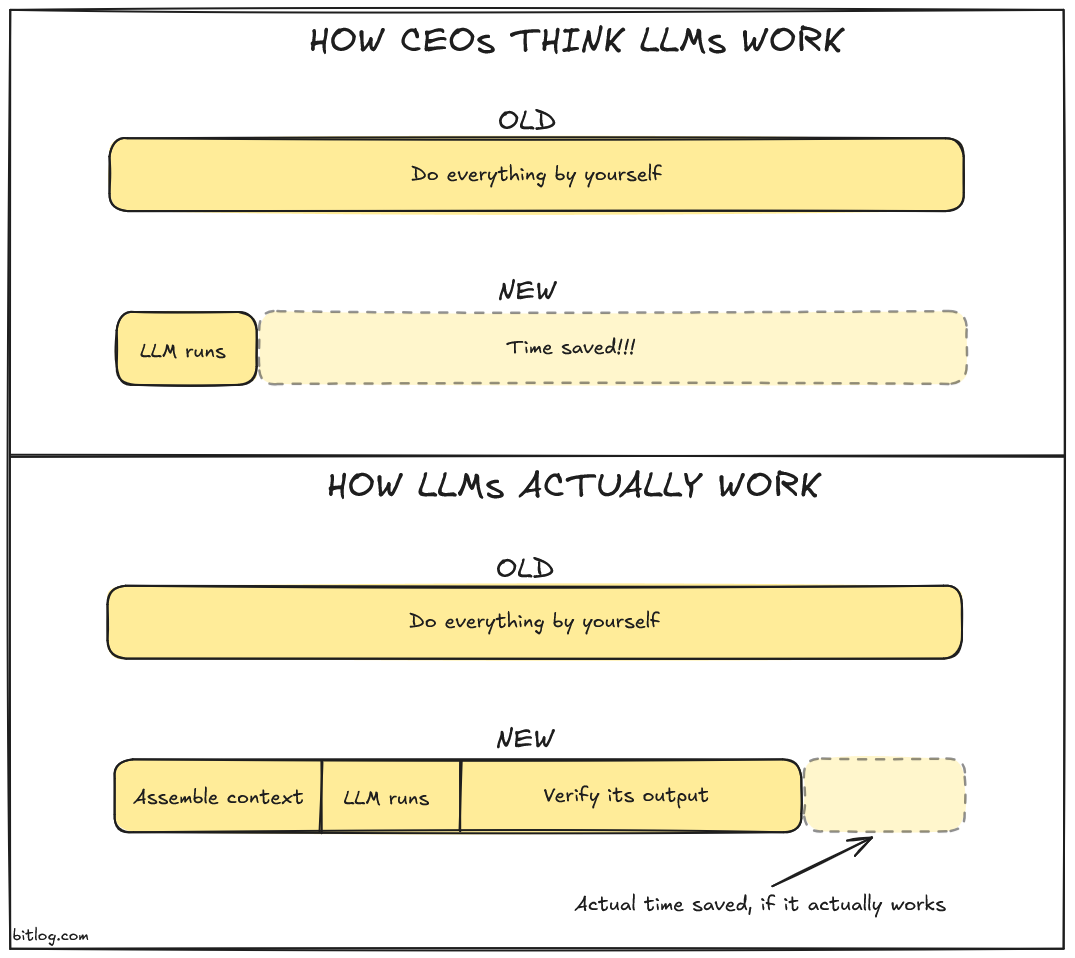
This diagram isn't meant to be pixel perfect. But I stand by the idea; for each LLM prompt, there is some intrinsic amount of context building and some intrinsic amount of verification. And if the output is too far from the desired result, then you're likely losing time.
If you want to break outside of the tech sphere, go talk to a competent lawyer about how useful they find LLMs. They're great, they save so much time! You can summarize really complex documents and generate briefs and do all of these other things! But you need to check every single thing that it outputs. You don't want to build your argument on a hallucinated case or an incorrect summary. You don't want to email an opposing council LLM slop.
What the hell? Why can LLMs solve math problems, but you can't rely on them to build a legal case without obsessively double-checking everything they do? Why can an LLM beat software engineers at a coding competition, but it can't build a simple presentation, a task that many people might delegate to an intern?
Let's revisit the two questions I wrote above. They explain the whole story.
- How easily can the LLM supplement its context?
- How quickly can the LLM verify its output?
And let's look at this through the lens of "Build a presentation with a single prompt." Let's really consider everything that you would need to build a successful presentation.
How easily can the LLM supplement its context?
Ok, what context is required to build a presentation in a business setting? Let's say that you're building a pitch deck for a new product offering, and you want potential customers to buy. Your customers might want to know…
- What problem they are currently experiencing.
- What value the new product offering delivers.
- A high-level overview of how the product works.
- Data that reinforces your story.
- Industry research explaining how similar companies solve this problem.
- Social proof from someone that tried the product.
- The story about how they successfully migrate to the project.
- Any offers, trials, concierge services, etc that make it easier to perform a pilot project for the service.
To build a successful presentation, you might need to additionally consider…
- How long is the scheduled time?
- Is there anything that would piss off your investors?
- Is there anything that would piss off key stakeholders?
- Do you know something about the audience that should be incorporated into the presentation, like their tech stack, stated preferences, etc?
- Do you have the ability to request that new art assets be made, or are you stuck working from some pre-canned set?
You also might not want them to know a few things.
- That you'd accept a steeper discount if they said they were trying a competitor.
- There's a feature that you're pitching that is still technically a roadmap feature and not code complete.
- Everything is a giant shitshow and we're just keeping it together for public appearances.
And the list goes on. So can the LLM easily supplement its context? Obviously not! The LLM might need to snake its tendrils into every single data source that your company has, including the brains of people who work there. And at a large organization, you will have so much data that it cannot fit into the context window of an LLM. So now the LLM needs to solve the open research question of "how do I find the exact right context that I need to answer all of these questions?"
How quickly can the LLM verify its output?
How do you need to verify a presentation that you didn't write?
First, you need to flip through the presentation. Look for any weird outputs. Are there overlapping regions? Things that are a little too close? When you put two images next to each other, do they visually clash in some way? Some of this could be handled by the LLM but some of it is just the human experience.
Then you need to consider the structure. Is this a compelling pitch? Is this ordered correctly? Should any slides be omitted? Is anything missing?
Then you need to nitpick the content. Are all of the sentences correct? Is it using good word choices throughout the presentation? Did it misunderstand any of the source material and needs to be reworked for accuracy?
And finally, you'll want to actually give the presentation slide-by-slide. Does it all flow naturally when spoken out loud? Are there any unnatural moments? Does anything need to be restructured or reworked?
So the LLM cannot really verify its output at all, so it can't iterate and recurse on the problem. But there are aspects that the LLM might be able to assist with, like finding source documents, answering questions about data that it can access, and generating the slides. So it's very likely that you could build the presentation faster, but there's also a tremendous amount of hidden work involved: uncovering the full context of your problem, what you need to present, and being a strong advocate for the audience in mapping the LLM output into a convincing presentation.
The cure for LLM psychosis
The cure is simply the ability to find the hidden work.
If the LLM can add to its own context via simple searches, or even perform its own logical thinking like building its own lemmas and theorems when investigating a math problem, then the problem is in the LLM's sweet spot. It doesn't need people at all, it can just churn by itself! However, if it needs to sort through more information than it can access within its own context, then the LLM is going to need extra assistance and there is hidden work.
If the LLM is working on a programming problem and can simply write its own unit tests and run the program on sample inputs to verify its own outputs, then you are in the LLM's sweet spot. However, once verification starts to have complex causes like "how do human beings feel when they view the output?" and "Does this otherwise-correct change introduce unwanted emergent behavior when run in the production system?", then there starts to be a lot of extra hidden work for getting the LLM to exist within an ecosystem.
